I've written a new Weave class for opencamlib which makes the waterline operation faster.
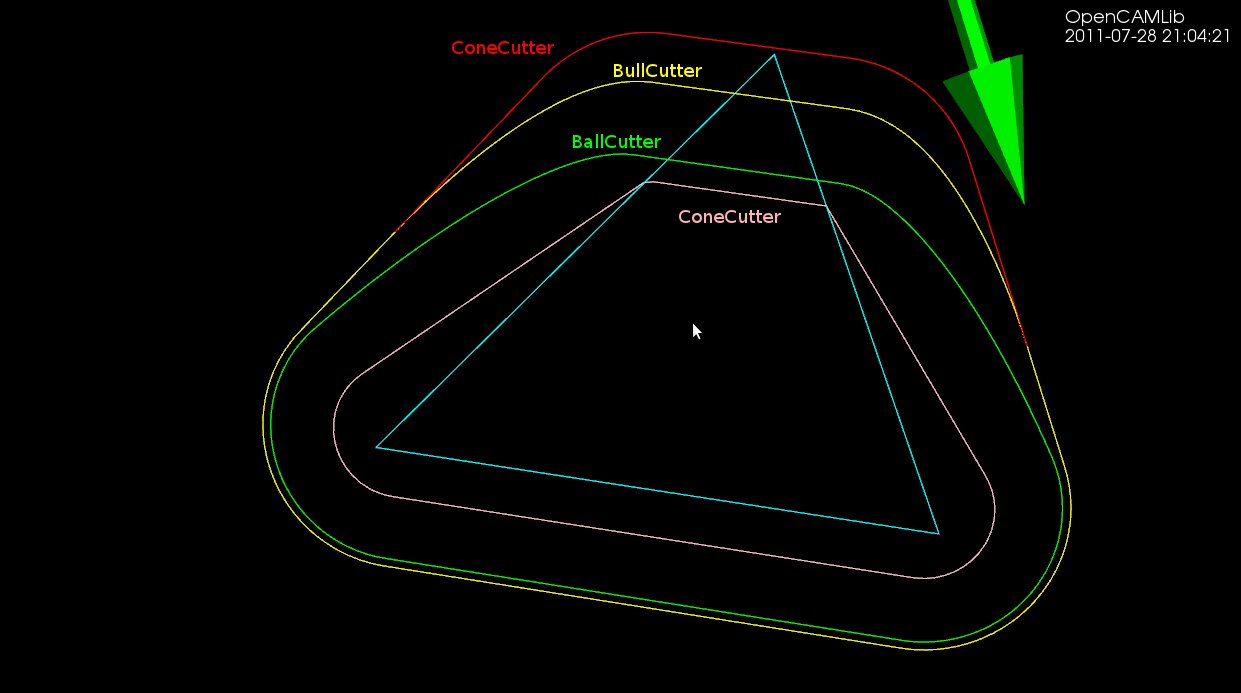
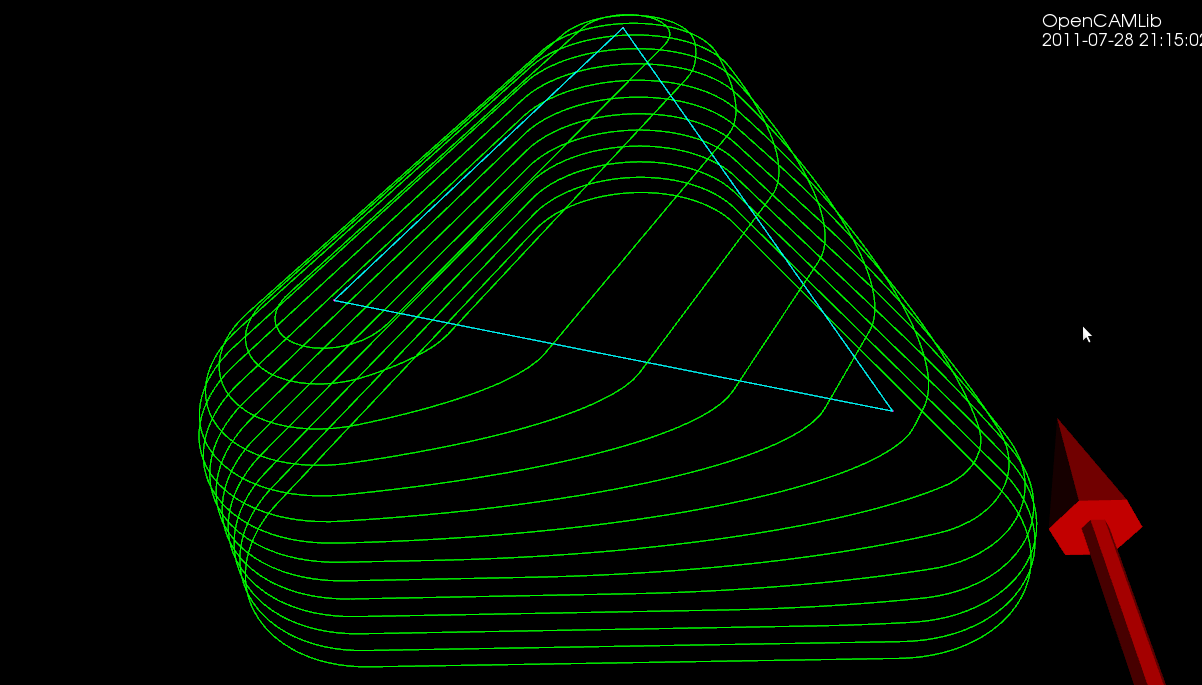
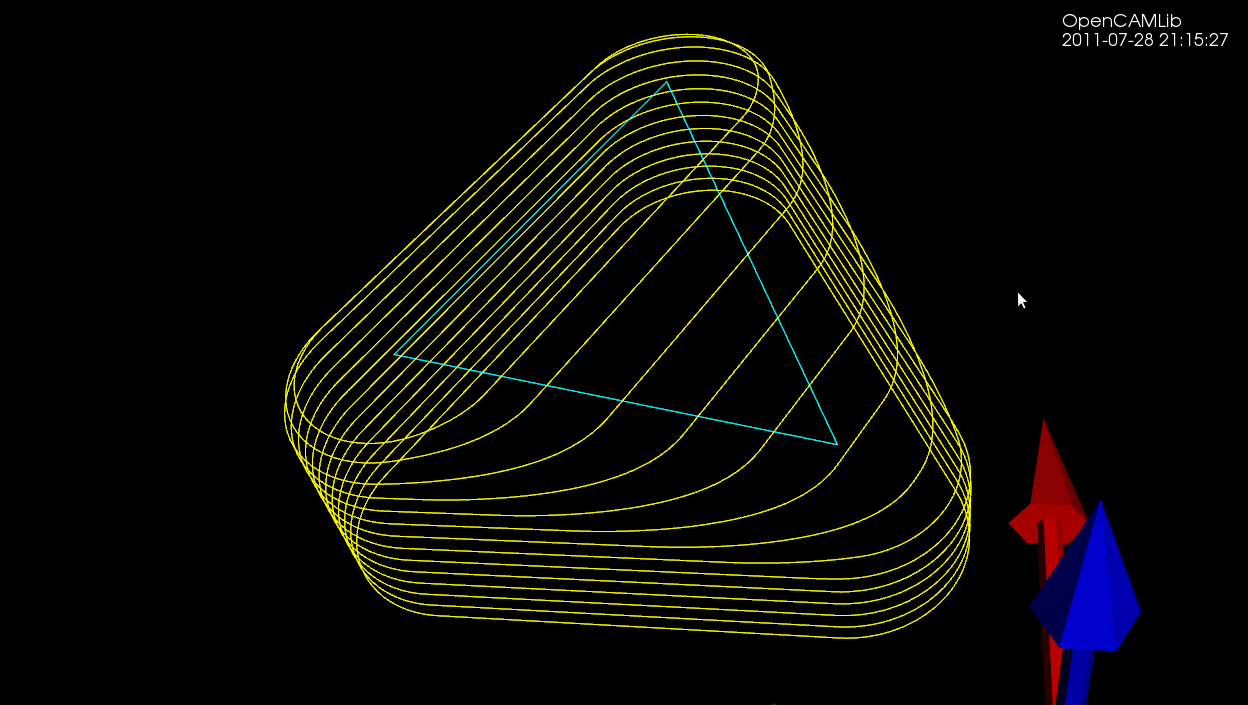
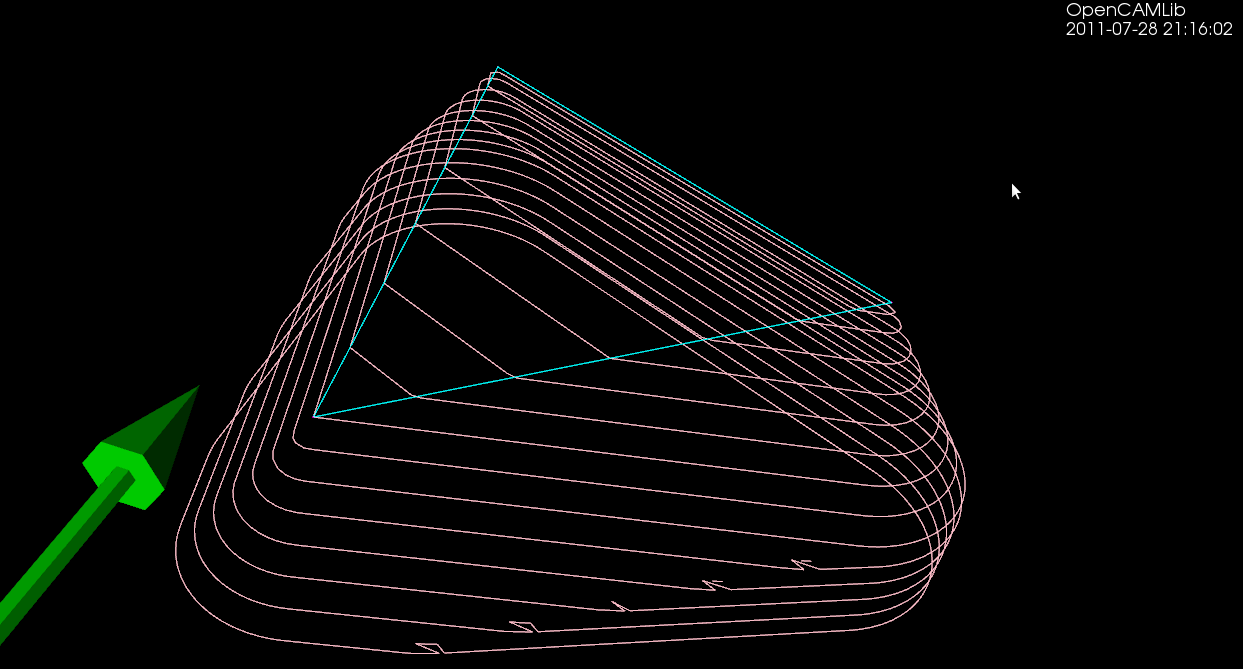
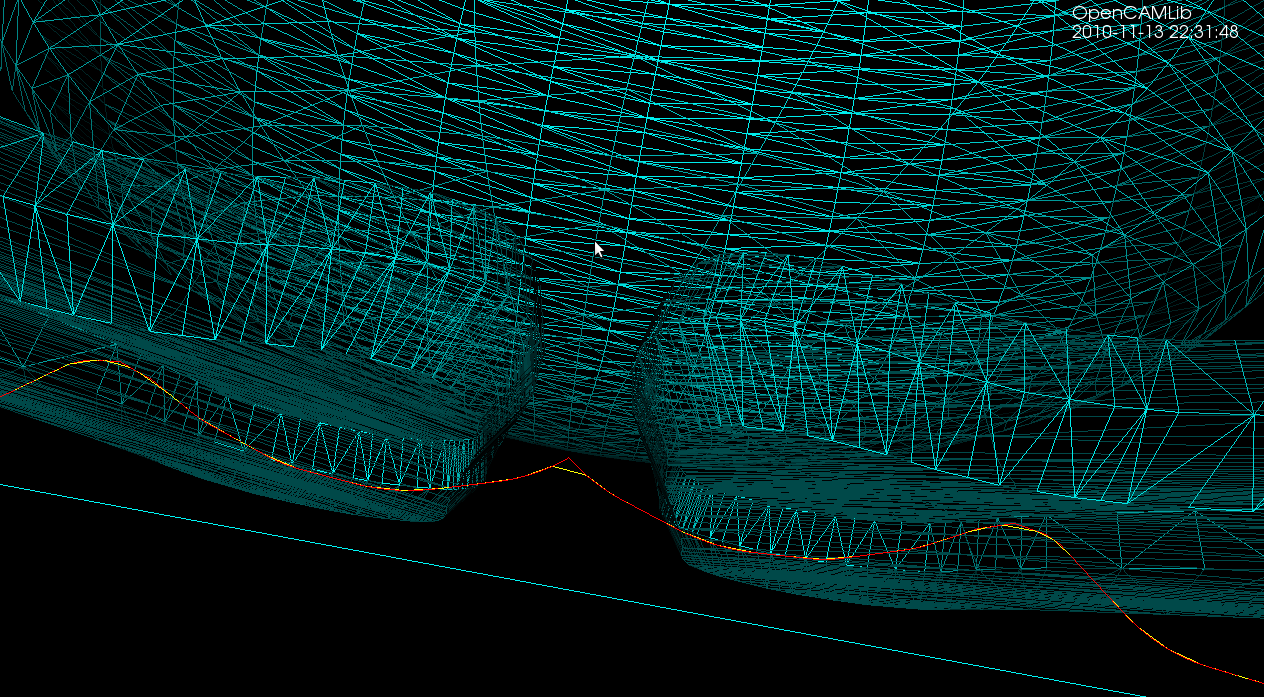
The first test-case is a single triangle, and we calculate a number of waterlines at different z-heights using a ball-cutter:

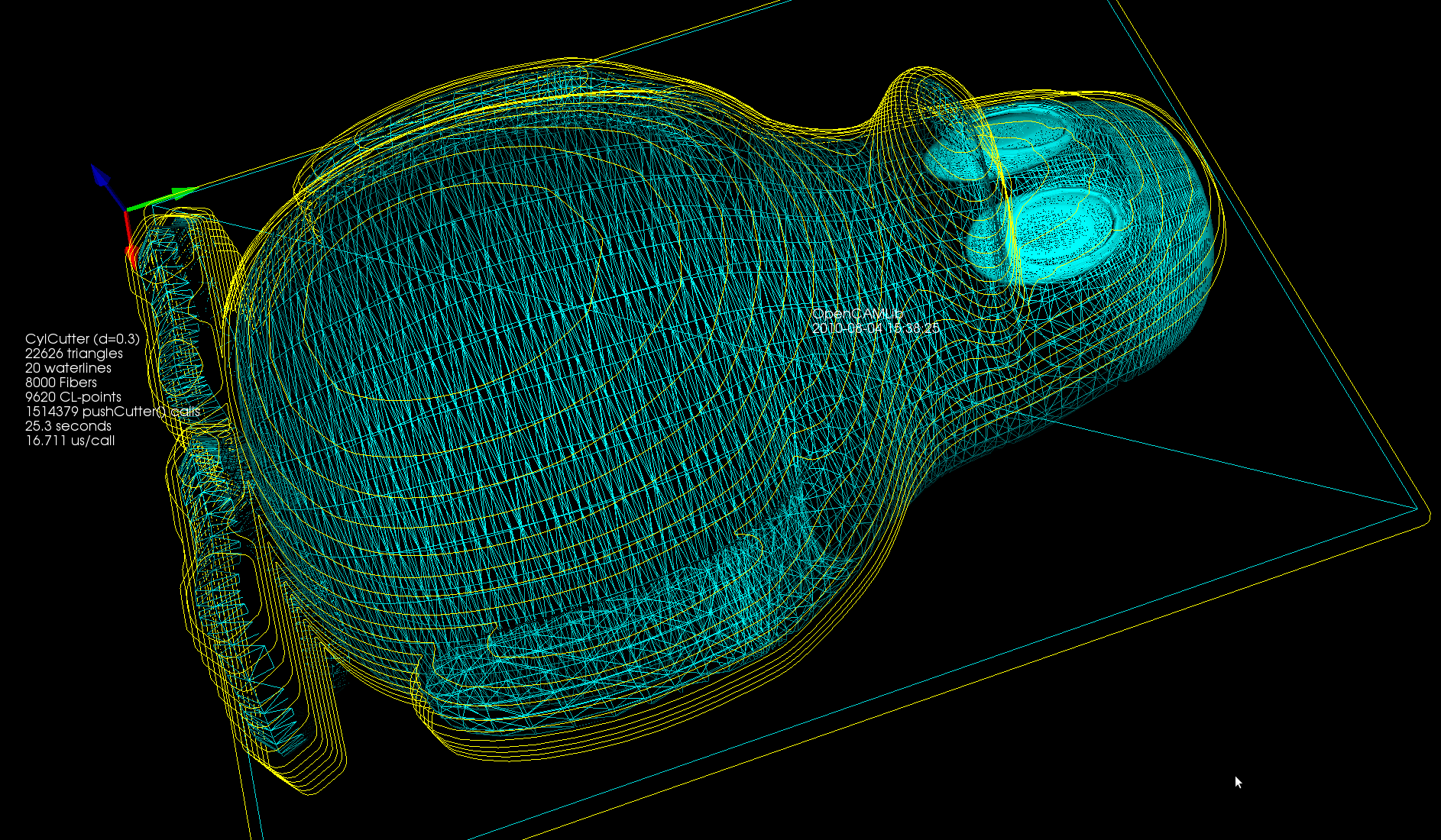
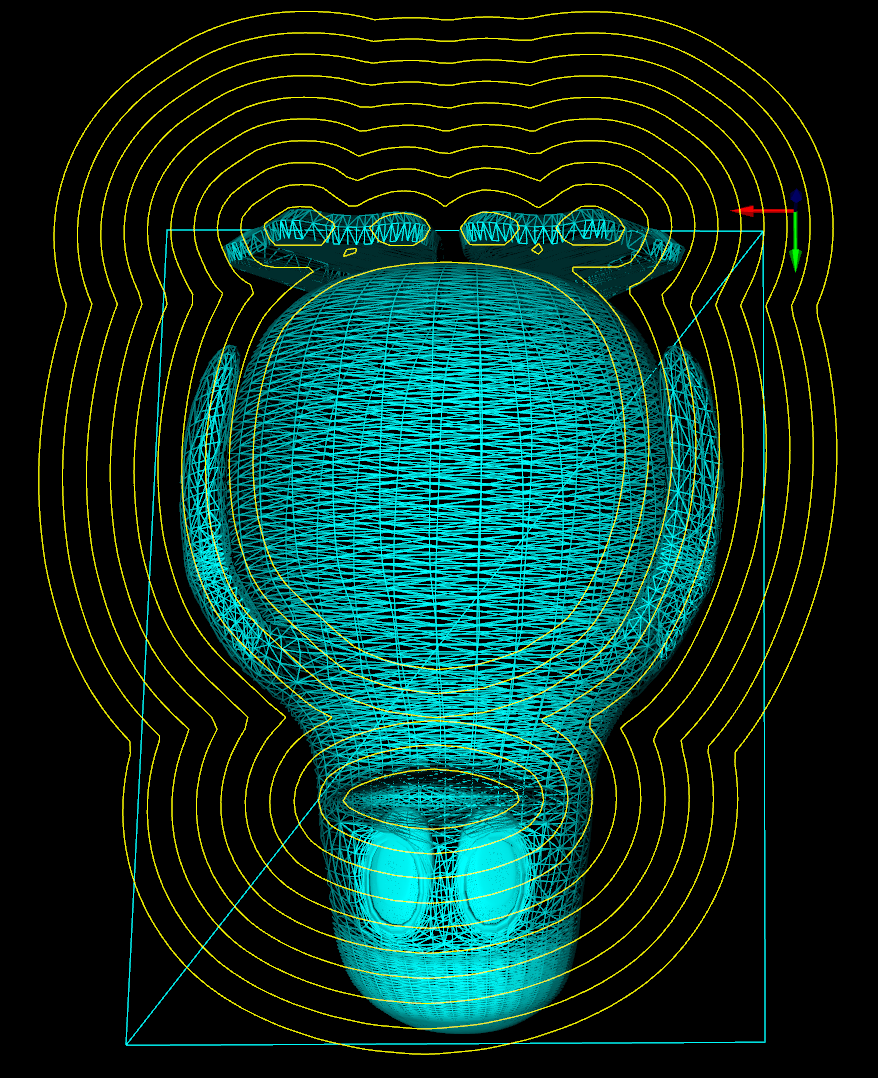
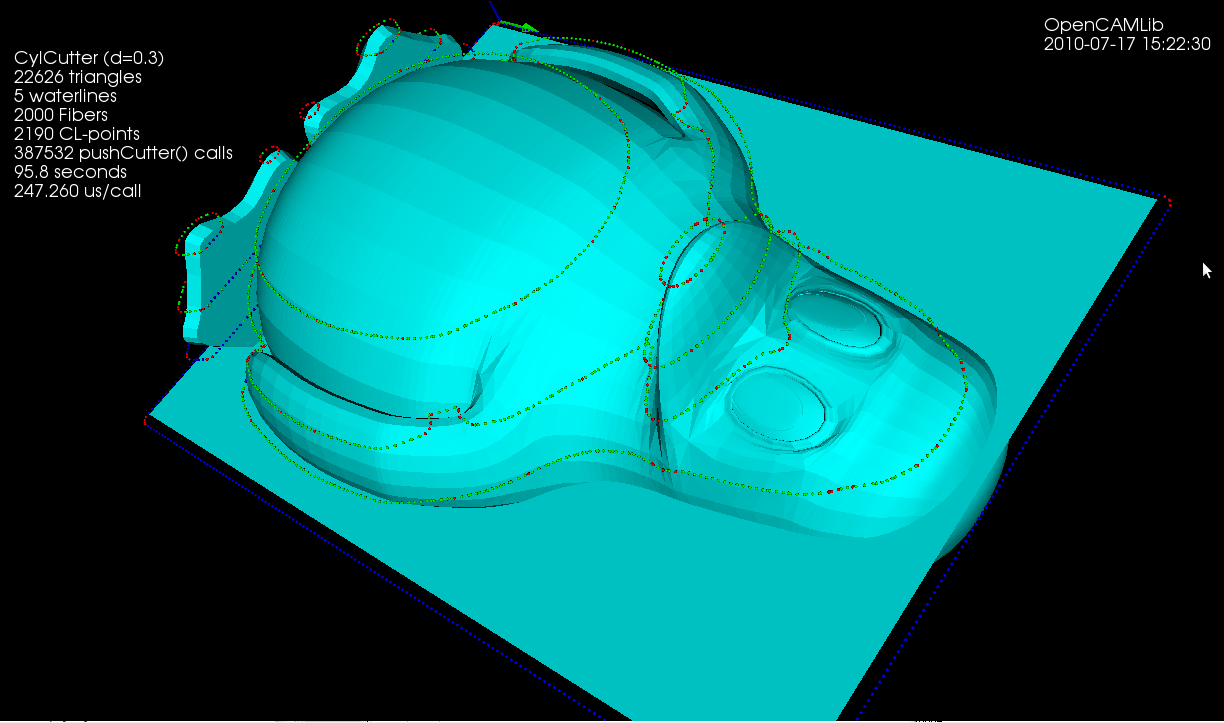
The second test-case is the Tux model where we calculate a single waterline at some z-height. Note how using the chosen ball-cutter at this particular height the waterline splits into two separate loops.

(the yellow line is a plain waterline and the red line is an adaptive Waterline, but that's not important here)
Here is the runtime data. The smaller symbols show results from the one-triangle test-case. The old algorithm(red data points and line) seems to be slower than O(N^2), with a pre-factor of about 2 milliseconds. The time data for the new algorithm (green) fits an O(N^2) line better and has an almost 10-fold faster pre-factor of around 0.25 ms.
The speedup for the Tux model (large symbols) is even greater. With the old algorithm the slope of the data points (pink) looks much worse than N^2 and runtimes quickly reach a minute or more. With the new algorithm (big light green symbols) the runtime stays under 100s even at 200 fibers/mm.

This speedup was achieved by building a weave which is a directed half-edge graph, instead of the old undirected graph. The old algorithm first used connected_components (time complexity O(V + E)) to split the weave into its connected components. For each component a planar embedding was then constructed (time complexity ??), and the toolpath loop extracted with planar_face_traversal (time complexity O(V+E)).
In the new Weave, each edge has a "next" pointer pointing to the next edge of the face. This means we can extract the toolpath loop by following the "next" pointer until we find the next CL-point. Effectively the planar embedding is now contained in the graph datastructure and does not have to be computed separately. This also saves work since we don't have to traverse faces which do not produce toolpaths. This new solution to the weave point-order problemdeserves its own post in the near future - stay tuned...




















{kind=link}
{kind=link}