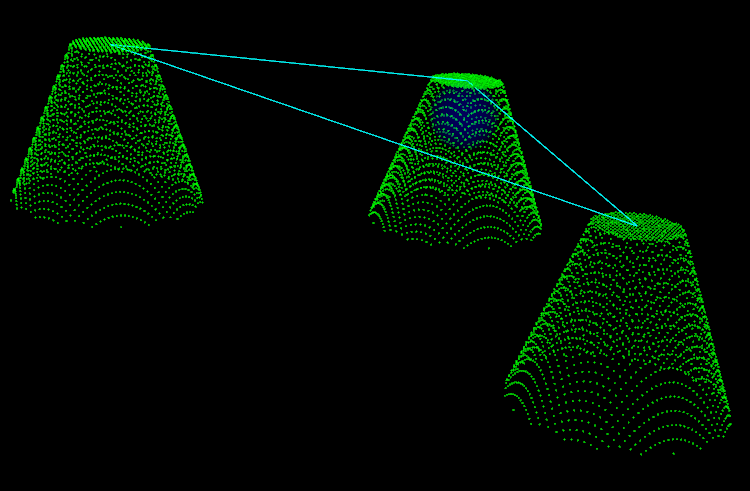
When generating toolpaths with drop-cutter ("axial tool-projection", if you like fancy words) the path ends up being composed of lots of short linear segments. It makes sense to filter this list of points and take out any middle points that lie on a straight line between neighboring points. Here's a first attempt at such a line-filter.
The lower points is the raw output from drop cutter, while the filtered points are offset vertically for clarity. There are 6611 CL-points in the raw data, but only 401 CL-points after filtering.
The next step is to come up with an arc-filter which detects circular arcs in the list of CL-points. All CNC-machines have G2/3 circular arc motion in the principal planes (xy, xz, yz). Then the number of moves will go even further down from 401 points.
This is just something to live with, having chosen the triangulated model approach to CAM. First we have pure and exact shapes in CAD which get tessellated into zillions of tiny triangles, from these we generate a sampled toolpath consisting of lots and lots of points, and finally we filter to get back those "pure" "exact" and "nice" line-segments and arcs.

The relevant part of the code looks like this. It might be a bit prettier to use the remove_if STL algorithm? Also, there's no check that p1 actually lies between p0 and p2.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | typedef std::list<clpoint>::iterator cl_itr; cl_itr p0 = clpoints.begin(); cl_itr p1 = clpoints.begin(); p1++; cl_itr p2 = p1; p2++; for( ; p2 != clpoints.end(); ) { Point p = p1->closestPoint(*p0, *p2); if ( (p- *p1).norm() < tol ) { // p1 is to be removed p1 = clpoints.erase(p1); p2++; } else { p0++; p1++; p2++; } } |
full code here.











{kind=link}